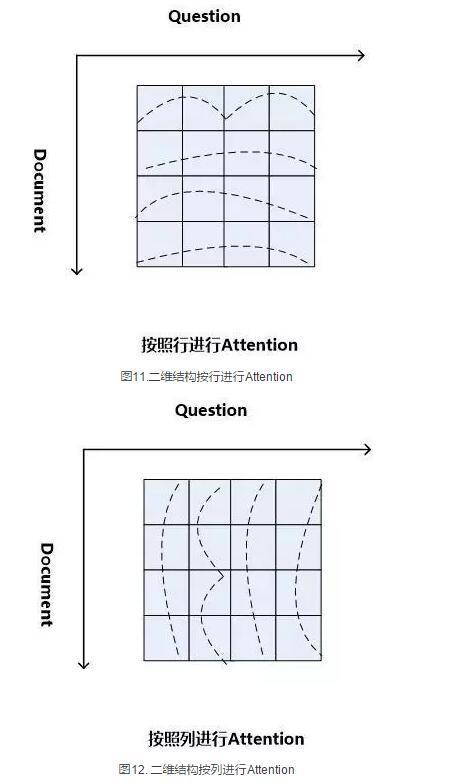
 Consensus Attention 模型(后文简称CA Reader,参考文献6)、Attention-over-Attention模型(后文简称AOA Reader,参考文献7)和Match-LSTM模型(参考文献8)基本都符合二维匹配结构的范式,其主要区别在于Attention计算机制的差异上。CA Reader按照列的方式进行Attention计算,然后对每一行文档单词对应的针对问题中每个单词的Attention向量,采取一些启发规则的方式比如取行向量中最大值或者平均值等方式获得文档每个单词对应的概率值。AOA Reader则对CA Reader进行了改进,同时结合了按照列和按照行的方式进行Attention计算,核心思想是把启发规则改为由按行计算的Attention值转换成的系数,然后用对按列计算出的Attention加权平均的计算方式获得文档每个单词对应的概率值。Match-LSTM模型则是按行进行Attention计算,同样地把这些Attention值转换成列的系数,不过与AOA不同的是,这些系数用来和问题中每个单词的Word Embedding相乘并对Word Embedding向量加权求和,拟合出整个问题的综合语义Word Embedding(类似于“问题表示方法:模型二”思路),并和文章中每个单词的Word Embedding进行合并,构造出另外一个LSTM结构,在这个LSTM结构基础上去预测哪个或者那些单词应该是正确答案。
Consensus Attention 模型(后文简称CA Reader,参考文献6)、Attention-over-Attention模型(后文简称AOA Reader,参考文献7)和Match-LSTM模型(参考文献8)基本都符合二维匹配结构的范式,其主要区别在于Attention计算机制的差异上。CA Reader按照列的方式进行Attention计算,然后对每一行文档单词对应的针对问题中每个单词的Attention向量,采取一些启发规则的方式比如取行向量中最大值或者平均值等方式获得文档每个单词对应的概率值。AOA Reader则对CA Reader进行了改进,同时结合了按照列和按照行的方式进行Attention计算,核心思想是把启发规则改为由按行计算的Attention值转换成的系数,然后用对按列计算出的Attention加权平均的计算方式获得文档每个单词对应的概率值。Match-LSTM模型则是按行进行Attention计算,同样地把这些Attention值转换成列的系数,不过与AOA不同的是,这些系数用来和问题中每个单词的Word Embedding相乘并对Word Embedding向量加权求和,拟合出整个问题的综合语义Word Embedding(类似于“问题表示方法:模型二”思路),并和文章中每个单词的Word Embedding进行合并,构造出另外一个LSTM结构,在这个LSTM结构基础上去预测哪个或者那些单词应该是正确答案。
由于二维匹配模型将问题由整体表达语义的一维结构转换成为按照问题中每个单词及其上下文的语义的二维结构,明确引入了更多细节信息,所以整体而言模型效果要稍优于一维匹配模型。
从上面的具体模型介绍可以看出,目前二维匹配模型相关工作还不多,而且都集中在二维结构的Attention计算机制上,由于模型的复杂性比较高,还有很多很明显的值得改进的思路可以引入。最直观的改进就是探索新的匹配函数,比如可以摸索双线性函数在二维结构下的效果等;再比如可以引入多层网络结构,这样将推理模型加入到阅读理解解决方案中等。可以预见,类似的思路很快会被探索。
3 机器阅读理解中的推理过程
人在理解阅读文章内容的时候,推理过程几乎是无处不在的,没有推理几乎可以断定人是无法完全理解内容的,对于机器也是如此。比如对于图1中所展示的人工合成任务的例子,所提的问题是问苹果在什么地方,而文章表达内容中,刚开始苹果在厨房,Sam将其拿到了卧室,所以不做推理的话,很可能会得出“苹果在厨房”的错误结论。
乍一看“推理过程”是个很玄妙而且说不太清楚的过程,因为自然语言文本不像一阶逻辑那样,已经明确地定义出符号以及表达出符号之间的逻辑关系,可以在明确的符号及其关系上进行推理,自然语言表达有相当大的模糊性,所以其推理过程一直是很难处理好的问题。
现有的工作中,记忆网络(Memory Networks,参考文献9)、GA Reader、Iterative Alternating神经网络(后文简称IA Reader,参考文献10)以及AMRNN都直接在网络结构中体现了这种推理策略。一般而言,机器阅读理解过程网络结构中的深层网络都是为了进行文本推理而设计的,就是说,通过加深网络层数来模拟不断增加的推理步骤。
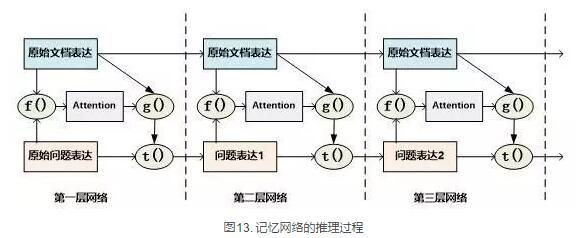 记忆网络是最早提出推理过程的模型,对后续其它模型有重要的影响。对于记忆网络模型来说,其第一层网络的推理过程(Layer-Wise RNN模式)如下(参考图13):首先根据原始问题的Word Embedding表达方式以及文档的原始表达,通过f函数计算文档单词的Attention概率,然后g函数利用文章原始表达和Attention信息,计算文档新的表达方式,这里一般g函数是加权求和函数。而t函数则根据文档新的表达方式以及原始问题表达方式,推理出问题和文档最终的新表达方式,这里t函数实际上就是通过两者Word Embedding的逐位相加实现的。t函数的输出更新下一层网络问题的表达方式。这样就通过隐式地内部更新文档和显示地更新问题的表达方式实现了一次推理过程,后续每层网络推理过程就是反复重复这个过程,通过多层网络,就实现了不断通过推理更改文档和问题的表达方式。
记忆网络是最早提出推理过程的模型,对后续其它模型有重要的影响。对于记忆网络模型来说,其第一层网络的推理过程(Layer-Wise RNN模式)如下(参考图13):首先根据原始问题的Word Embedding表达方式以及文档的原始表达,通过f函数计算文档单词的Attention概率,然后g函数利用文章原始表达和Attention信息,计算文档新的表达方式,这里一般g函数是加权求和函数。而t函数则根据文档新的表达方式以及原始问题表达方式,推理出问题和文档最终的新表达方式,这里t函数实际上就是通过两者Word Embedding的逐位相加实现的。t函数的输出更新下一层网络问题的表达方式。这样就通过隐式地内部更新文档和显示地更新问题的表达方式实现了一次推理过程,后续每层网络推理过程就是反复重复这个过程,通过多层网络,就实现了不断通过推理更改文档和问题的表达方式。
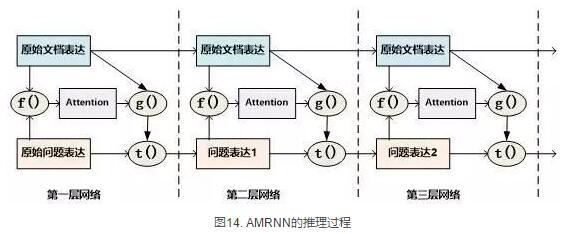 AMRNN模型的推理过程明显受到了记忆网络的影响,图14通过摒除论文中与记忆网络不同的表面表述方式,抽象出了其推理过程,可以看出,其基本结构与记忆网络的Layer-Wise RNN模式是完全相同的,唯一的区别是:记忆网络在拟合文档或者问题表示的时候是通过单词的Word Embedding简单叠加的方式,而AMRNN则是采用了RNN结构来推导文章和问题的表示。所以AMRNN模型可以近似理解为AS Reader的基础网络结构加上记忆网络的推理过程。
AMRNN模型的推理过程明显受到了记忆网络的影响,图14通过摒除论文中与记忆网络不同的表面表述方式,抽象出了其推理过程,可以看出,其基本结构与记忆网络的Layer-Wise RNN模式是完全相同的,唯一的区别是:记忆网络在拟合文档或者问题表示的时候是通过单词的Word Embedding简单叠加的方式,而AMRNN则是采用了RNN结构来推导文章和问题的表示。所以AMRNN模型可以近似理解为AS Reader的基础网络结构加上记忆网络的推理过程。
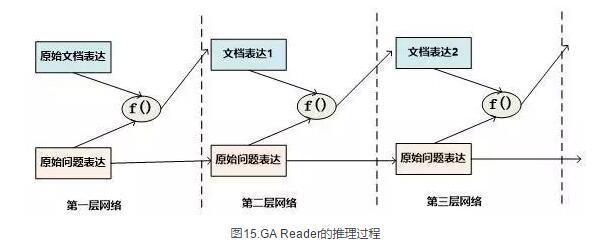 GA Reader的推理过程相对简洁,其示意图如图15所示。它的第一层网络推理过程如下:其每层推理网络的问题表达都是原始问题表达方式,在推理过程中不变。而f函数结合原始问题表达和文档表达来更新文档表达到新的形式,具体而言,f函数就是上文所述的被称为Gated-Attention模型的匹配函数,其计算过程为Di和Q两个向量对应维度数值逐位相乘,这样形成新的文档表达。其它层的推理过程与此相同。
GA Reader的推理过程相对简洁,其示意图如图15所示。它的第一层网络推理过程如下:其每层推理网络的问题表达都是原始问题表达方式,在推理过程中不变。而f函数结合原始问题表达和文档表达来更新文档表达到新的形式,具体而言,f函数就是上文所述的被称为Gated-Attention模型的匹配函数,其计算过程为Di和Q两个向量对应维度数值逐位相乘,这样形成新的文档表达。其它层的推理过程与此相同。
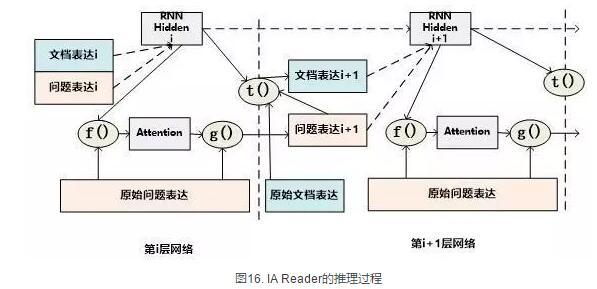 IA Reader的推理结构相对复杂,其不同网络层是由RNN串接起来的,图16中展示了从第i层神经网络到第i+1层神经网络的推理过程,其中虚线部分是RNN的组织结构,每一层RNN结构是由新的文档表达和问题表达作为RNN的输入数据。其推理过程如下:对于第i层网络来说,首先根据RNN输入信息,就是第i层的文档表达和问题表达,更新隐层状态信息;然后f函数根据更新后的隐层状态信息以及原始的问题表达,计算问题中词汇的新的attention信息;g函数根据新的attention信息更新原始问题的表达形式,形成第i+1层网络的新的问题表达,g函数一般采取加权求和的计算方式;在获得了第i+1层新的问题表达后,t函数根据第i层RNN隐层神经元信息以及第i+1层网络新的问题表达形式,更新原始文档表达形成第i+1层文档的新表达形式。这样,第i+1层的问题表达和文档表达都获得了更新,完成了一次推理过程。后面的推理过程都遵循如此步骤来完成多步推理。
IA Reader的推理结构相对复杂,其不同网络层是由RNN串接起来的,图16中展示了从第i层神经网络到第i+1层神经网络的推理过程,其中虚线部分是RNN的组织结构,每一层RNN结构是由新的文档表达和问题表达作为RNN的输入数据。其推理过程如下:对于第i层网络来说,首先根据RNN输入信息,就是第i层的文档表达和问题表达,更新隐层状态信息;然后f函数根据更新后的隐层状态信息以及原始的问题表达,计算问题中词汇的新的attention信息;g函数根据新的attention信息更新原始问题的表达形式,形成第i+1层网络的新的问题表达,g函数一般采取加权求和的计算方式;在获得了第i+1层新的问题表达后,t函数根据第i层RNN隐层神经元信息以及第i+1层网络新的问题表达形式,更新原始文档表达形成第i+1层文档的新表达形式。这样,第i+1层的问题表达和文档表达都获得了更新,完成了一次推理过程。后面的推理过程都遵循如此步骤来完成多步推理。
从上述推理机制可以看出,尽管不同模型都有差异,但是其中也有很多共性的部分。一种常见的推理策略往往是通过多轮迭代,不断更新注意力模型的注意焦点来更新问题和文档的Document Embedding表达方式,即通过注意力的不断转换来实现所谓的“推理过程”。
推理过程对于有一定难度的问题来说具有很明显的帮助作用,对于简单问题则作用不明显。当然,这与数据集难度有一定关系,比如研究证明(参考文献10),CNN数据集整体偏容易,所以正确回答问题不需要复杂的推理步骤也能做得很好。而在CBT数据集上,加上推理过程和不加推理过程进行效果对比,在评价指标上会增加2.5%到5%个绝对百分点的提升。
4 其它模型
上文对目前主流的技术思路进行了归纳及抽象并进行了技术归类,除了上述的三种技术思路外,还有一些比较重要的工作在模型思路上不能归于上述分类中,本节对这些模型进行简述,具体模型主要包括EpiReader(参考文献11)和动态实体表示模型(Dynamic Entity Representation,后文简称DER模型,参考文献12)。
EpiReader是目前机器阅读理解模型中效果最好的模型之一,其思路相当于使用AS Reader的模型先提供若干候选答案,然后再对候选答案用假设检验的验证方式再次确认来获得正确答案。假设检验采用了将候选答案替换掉问题中的PlaceHolder占位符,即假设某个候选答案就是正确答案,形成完整的问题句子,然后通过判断问题句和文章中每个句子多大程度上是语义蕴含(Entailment)的关系来做综合判断,找出经过检验最合理的候选答案作为正确答案。这从技术思路上其实是采用了多模型融合的思路,本质上和多Reader进行模型Ensemble起到了异曲同工的作用,可以将其归为多模型Ensemble的集成方案,但是其假设检验过程模型相对复杂,而效果相比模型集成来说也不占优势,实际使用中其实不如直接采取某个模型Ensemble的方案更实用。
DER模型在阅读理解时,首先将文章中同一实体在文章中不同的出现位置标记出来,每个位置提取这一实体及其一定窗口大小对应的上下文内容,用双向RNN对这段信息进行编码,每个位置的包含这个实体的片段都编码完成后,根据这些编码信息与问题的相似性计算这个实体不同语言片段的Attention信息,并根据Attention信息综合出整篇文章中这个实体不同上下文的总的表示,然后根据这个表示和问题的语义相近程度选出最可能是答案的那个实体。DER模型尽管看上去和一维匹配模型差异很大,其实两者并没有本质区别,一维匹配模型在最后步骤相同单词的Attention概率合并过程其实和DER的做法是类似的。

