在自然语言处理领域,许多高难度的任务都可以归结进序列到序列(sequence to sequence)的框架中。
比如说,机器翻译任务表面上是将一种语言转换为另一种语言,本质上就是从一段不定长的序列转换为另一段不定长的序列。如今实现seq2seq最有效的方法即为LSTM,一种带门的RNN(Recurrent Neural Network,递归神经网络),它可以将源语言编码为一个固定长度含丰富语义的向量,然后作为解码网络的隐藏状态去生成目标语言。而Image Caption Generator(自动图像生成器)方法正是受到机器翻译中seq2seq进展的启发:何不将源语言信号替换成图像信号,这样就能够将机器翻译的任务转换也就是把图像转成自然语言,即图像自然语言描述。
可是简单地将图像信号直接作为输入是无法达到很好的效果,原因是原始的图像信号并不是一个紧致的表示,含有太多的噪声。所以需要引入DL(Deep Learning,深度学习)在机器视觉中最核心的部件:CNN(Convolutional Neural Network,卷积网络)。
在DCNN的高层神经元输出可以表示图像的紧致的高层语义信息,如今众多成功的机器视觉应用都得益于此,比如前段时间爆红的Prisma(《AI修图艺术:Prisma背后的奇妙算法》),其texture transfer(风格转换)算法正是巧妙的利用了含有高层语义的图像表示。
所以此图像文字描述方法的基本思想就是利用了DCNN生成图像的高层抽象语义向量,将其作为语言生成模型LSTM的输入进行sequence to sequence的转换,其结构图如下:
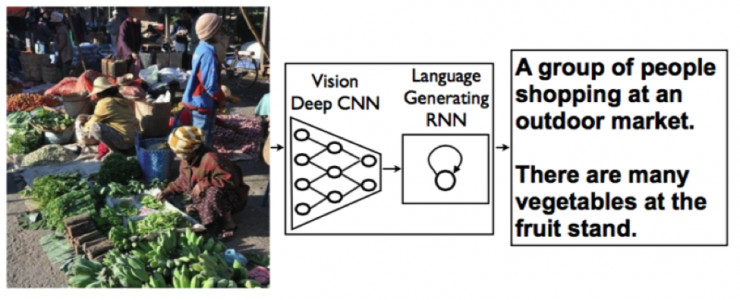
图1. 系统结构
此方法的巧妙之处在于将视觉和自然语言处理领域中最先进的两类网络连着在一起,各自负责其擅长的部分,同时进行端到端的训练学习。
Image Caption的神经网络学习可以用数学公式概括为:
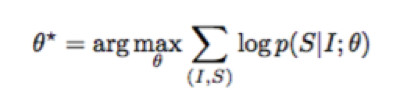
其中I为图片,S为生成的句子,θ为网络需要学习的参数,这个公式的含义指的是:学习最佳的网络参数θ最大化在给定图片下其生成正确描述的概率。同时由于语言句子的长度是不定长的,所以一般将其概率用链式法则写成:
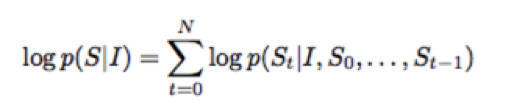
其中N为句子的长度,S_i为句子的每一个词。更具体的网络形式为下图:
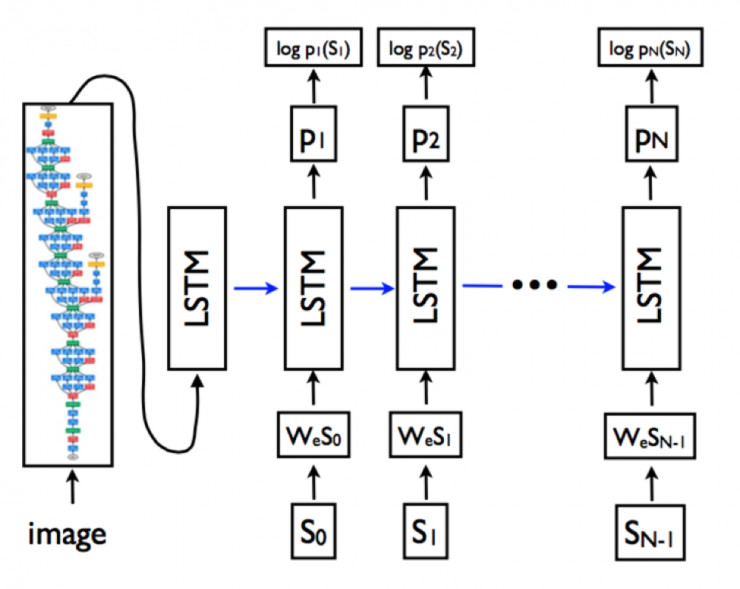
图2. 语言模型LSTM,图像模型CNN和词嵌入模型
上图将LSTM的recurrent connection(复现连接)以更加直观的展开形式画出来,在网络训练过程中,目标可以写为以下的损失函数:
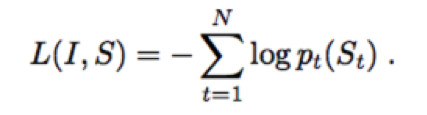
其目标是更新LSTM、CNN和词嵌入模型的参数,使得每一个正确的词出现的概率最大,也就是让此loss函数越小。除了LSTM、CNN模型的选择和词嵌入模型都会极大影响最后的效果,此方法最早发明时,最好的DCNN是2014年ImageNet竞赛的冠军网络GoogLeNet。而后,随着更强的CNN网络Inception V1到V3系列的出现,作者发现在此框架的Image Caption的效果也随之变得更好。这也是必然的,因为更强的CNN网络意味着输出的向量表示可以做到更好的图像高层语义表示。
作者在其开源的Tensorflow项目中号召大家去尝试现在最强的CNN分类网络Inception-Resnet-V2,看看是否会有效果的继续提升。对于词嵌入模型,最简单的方式是 one-hot-encoding的方法(向量中代表词的维度为1,其余为0),而此方法使用了一个更复杂的词嵌入模型,使得词嵌入模型也可以随着其他两个网络一起训练,训练出来的词嵌入模型表示被发现可以获取到自然语言的一些统计特性,比如以下的词在学习到的空间中是非常相近的,这符合自然语言中这些词的距离。

图3. 一些词在嵌入空间中的相近词
在最早的版本中,CNN模型使用的是在ImageNet数据库上预训练好的分类模型,在Image caption训练过程中其参数是不做更新的。而在最新的方法中,作者称在训练过程中更新CNN最高层的权重可以产生更好的效果,不过这些参数的更新需要在LSTM更新稳定后才能进行,不然LSTM的噪声会对CNN模型造成不可逆的影响。
视觉模型和语言生成模型进行端到端的联合训练有利于相互提升效果。例如在CNN模型中,可以将图像中更有利于“描述”而不是用于“分类”的信息迁移给语言模型,由于ImageNet的训练数据的类别空间中比较缺少颜色信息,所以在不使用联合训练的CNN模型的2015 CVPR版本中,并不会生成类似于“一辆蓝色和黄色的火车”这样的描述。当进行联合训练后,caption模型可以生成更精确、更细节化的句子,如下图所示:

图4. 初始模型和最新模型生成句子的对比
这让人会不禁产生一个疑问:现在的模型是否真的学会对图片中未曾见过的情境和交互生成全新的描述,还是只是简单的复述训练数据中的句子?这个问题关乎到算法是否真正理解了物体及其交互这个核心问题。
科学家们给出了一个令人振奋的答案: Yes。
如今的图像语言描述系统确实已经发展出自主产生全新的句子能力,例如下图粗体的描述为不在数据库中的标注句子:

图5. 生成的语言描述 (粗体的句子为不在训练数据中的全新句子)
其生成全新描述过程可以用下图进行很好的阐述:
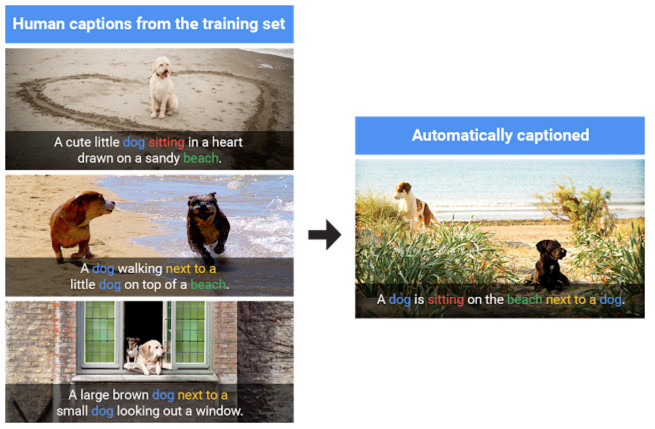
图6. 模型从训练数据提供的概念中生成全新的描述
此领域的突破同时也得益于如今标注数据的增长,作者们通过实验证明:越多的图像描述样本,越是可以极大地增强如今已经效果不错的图像描述算法。
这也是Goolge的研究者开源其系统的原因,其希望让更多人参与到此领域的研究中。
视觉信息约占人类从外界获取信息的⅔,所以机器视觉的重要性自然不言而喻;语言作为人之所以为人的标志,因而自然语言处理被称为人工智能皇冠上最亮的明珠。Image caption作为一个连接此两个领域的问题,其突破性的进展更深层次的意义在于表明人工智能的全面进步。

